
애플 M4에서 Object Detection 항목의 성능이 약 두배 가량 올랐고, SME 명령어셋 채용 덕분인걸로 밝혀짐
뉴럴넷에서 많이 하는 행렬 연산을 가속하는 명령어셋임 (물론 이거 빼도 성능향상 16.5%임)

트위터에서 몇몇사람들이 해당 항목 제외하고 계산해야한다면서 빼고 계산하기 시작함
(어떻게든 차이 작아 보이게 하려고 M3 Max 점수 가져오고 계산도 틀려서 나중에 정정한건 유머)

띠용?
알고보니 AMD도 젠3에서 젠4로 넘어가면서
AVX-VNNI 라는 x86에서 뉴럴넷 가속하기 위한 행렬 연산 명령어셋 넣어서 성능 향상된걸로 밝혀짐
심지어 애플보다 향상폭 더 큼

게다가 인텔도 로켓레이크로 넘어가면서 AVX-VNNI 명령어 채용으로 성능을 1.7배나 끌어올림 ㅋㅋㅋ

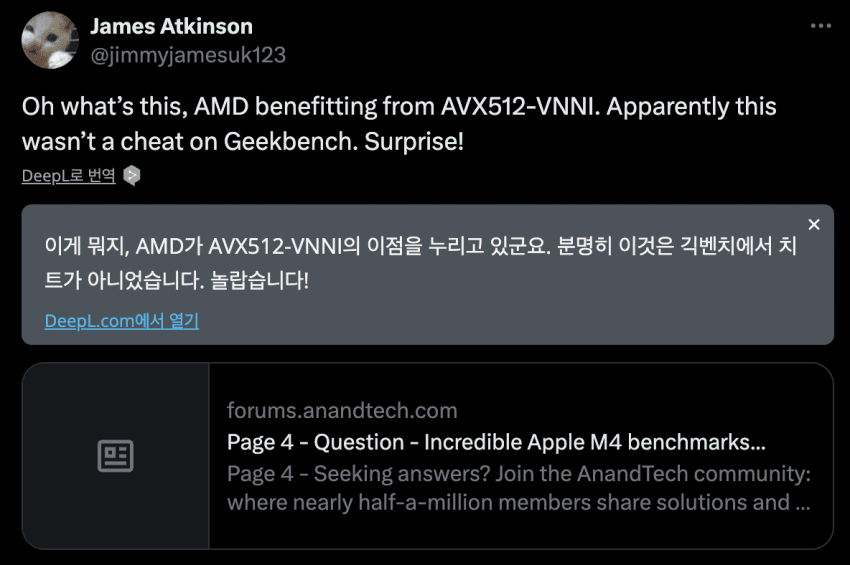
결국 CPU에 뉴럴넷 가속 연산 넣어서 점수 끌어올리던건 인텔, AMD가 이미 하던건데
애플이 했다는 이유만으로 갑자기 해당 항목 문제삼는게 이중적이라는 지적도 나옴
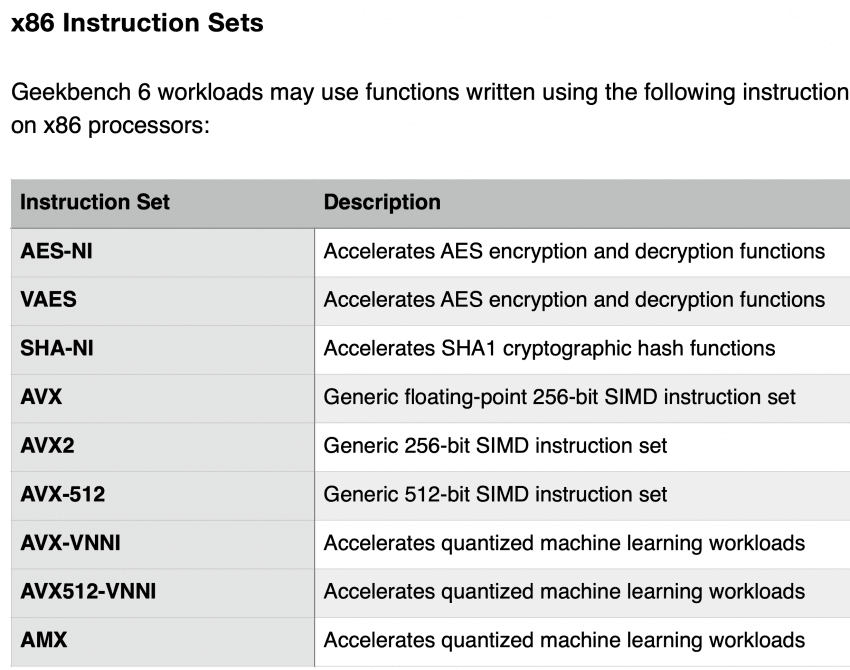
심지어 x86는 이미 이런 수많은 가속 명령어로 긱벤치 점수에서 이득을 취하는중 ㅋㅋ
애플이 SME 썼다고 항목 제외해야 한다는 논리면 저런 연산 쓰는 항목 싹다 제외해야 하는 게 맞다 ㅇㅇ
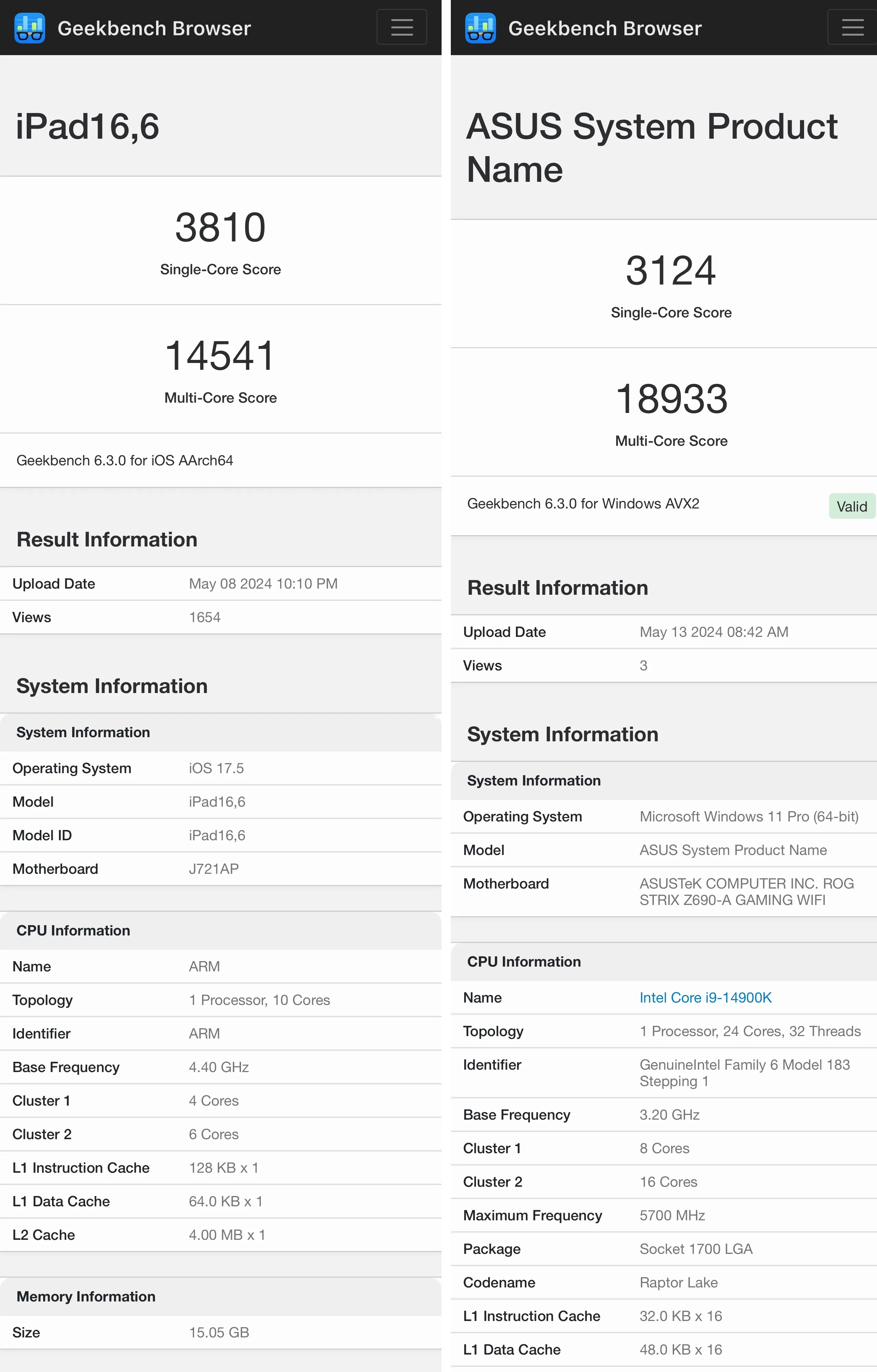


 커뮤맨 작성
커뮤맨 작성
















