
1. o3-mini(hard)에게 mac에서 o3-mini API를 사용해서 코드를 생성하고 바로 실행하는 프로그램을 UI와 함께 만들라고 지시
다음과 같은 내용에 대한 Python 스크립트를 작성해주세요:
HTML 파일을 로컬에서 서버로 실행하는 스크립트가 필요합니다. 이 HTML 파일에는 큰 텍스트 상자가 있어야 합니다. 텍스트 상자에 내용을 입력하고 제출 버튼을 누르면:
-해당 요청을 OpenAI의 o3-mini API로 전송해야 하며, medium reasoning_effort 설정을 사용합니다
-API로부터 받은 코드를 데스크톱의 임시 파일로 저장합니다
-새로운 파이썬 터미널에서 그 파일을 실행합니다
추가 세부사항:
-API 키는 ~/api_key 위치에서 찾을 수 있습니다
-API 요청 시 원시 코드만 반환하고 포매팅이나 마크다운을 전혀 포함하지 않도록 추가 프롬프팅을 넣어주세요
-Mac 노트북에서 실행될 예정입니다

2. 그렇게 해서 만든 코드
 3.
3.
3. o3-mini(hard)가 직접 만든 터미널
이제 저기에 아무거나 입력하고 submit을 누르면
o3-mini(medium) API를 통해 코드를 생성하고,
생성된 코드를 임시파일로 저장하고,
임시파일로 저장된 코드를 파이썬으로 실행하는 것 까지 수행
프롬프트에는 위처럼 간단하게 openai를 프린트하고 아무 숫자나 프린트하라고 시킴

4. 실행 결과
openai 41 이라고 결과가 나온 모습
(즉, o3-mini API로 프롬프트를 보내서 코드를 짰고, 그 코드의 실행 결과가 openai 41이 된 것)

5. 이제 좀 더 난이도를 높여서, o3-mini에게 너 자신의 GPQA 점수를 직접 평가하라는 프롬프트를 만듬
-특정 url로 들어가서 평가 데이터셋을 다운 받고, API 사용방법에 따라 제대로 코드를 짜야하고,
다운받은 데이터셋을 o3-mini(low) API로 보내서 결과를 얻고,
나온 결과를 Answer: 형태로 깔끔하게 나오게 해서 평가가 가능할 수 있게 해야함
그리고 async를 사용해서 병렬처리가 가능하게 하고, api 콜이 실패하지 않도록 robust하게 만들어야함
등의 지시 사항이 담김

6. 그렇게 해서 나온 결과
61.62%라고 점수가 바로 계산됨
자기 자신이 스스로를 원큐에 평가한 것
7. 그 뒤에 멘트들
"내년에는 모델에게 너 자신을 개선해라 라고 명령해봐야겠네요"
이 과정이 라이브에서 찐빠없이 이루어진게 개인적으론 매우 놀라웠음
o3-mini가 이정도면 o3는 그냥 말이 안되는 수준일듯
- o3 벤치마크가 가지는 의미
Codeforces, FrontierMath, GPQA 하나같이 다 인간 최상위권들 수준의 문제들임
어느 정도일까?
Codeforces : 코딩 고인물들만 참가하는 대회
여기서 99832명 중 50위 내, 즉 상위 0.05% 달성
보통 Candidate Master만 되도 인간 최상위권인데, 그 중에서만 따져도 0.7% 내에 들음
ELO 2500점만 되도 국제올림피아드 진출권이라는 걸 생각하면, 보통 인생 살면서 이 정도로 코딩 잘하는 사람은 보기도 힘듬
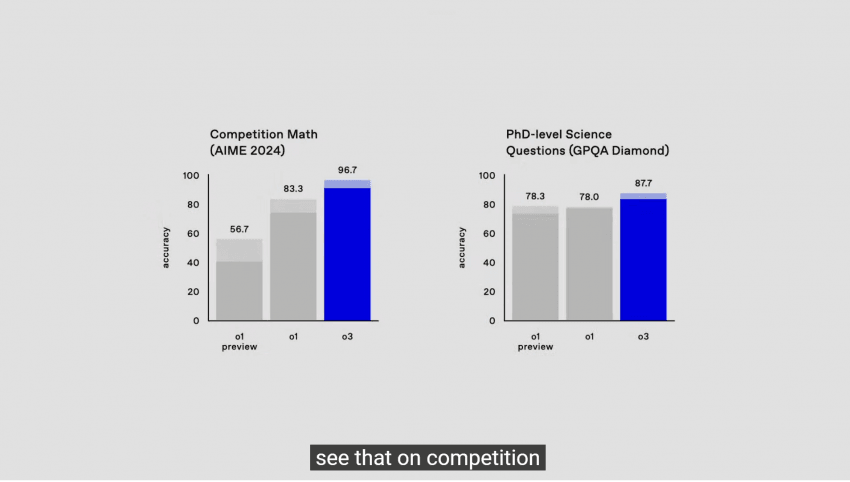
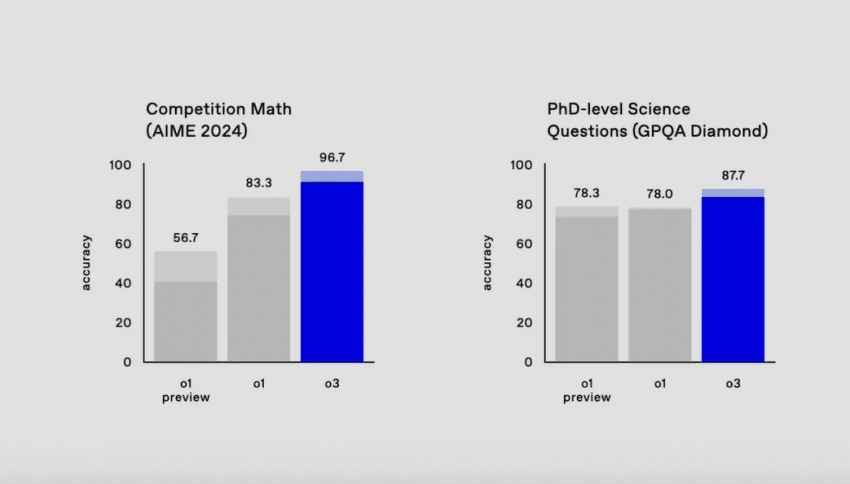
AIME(미국 수학 올림피아드) 96.7%, GPQA (박사 수준 추론 질문) 87.7%
웬만한 사람은 아무리 공부해도 이 정도에 도달하는 건 불가능
참고로 GPQA는 해당 분야 박사 학위도 평균 65%의 정답률을 보임
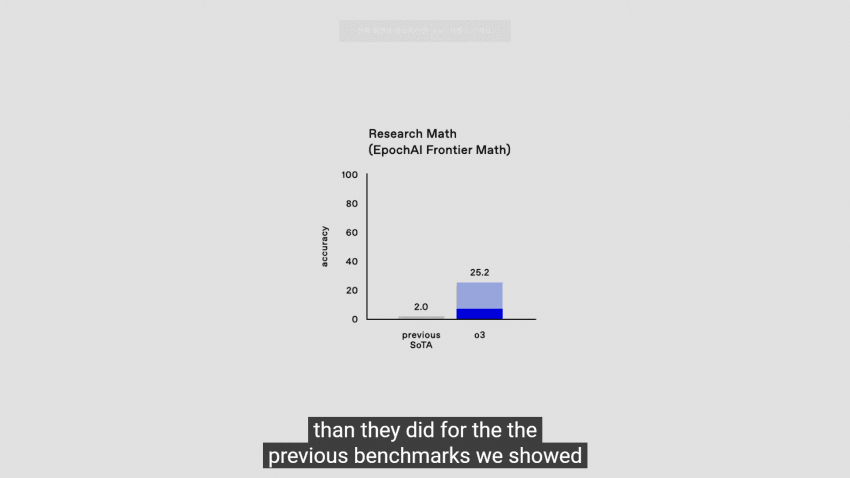
FrontierMath : 대놓고 현존하는(했던) 인공지능들 엿먹이려고 만든 수학 벤치마크
수학 평생 공부하면서 박사까지 전공한 사람들도 자기 분야랑 딱 맞는 거 아니면 못 푸는 문제들만 있음
공식 사이트(https://epoch.ai/frontiermath)에 있는 언급 :
Terence Tao : 이 문제들 ㅈㄴ 어려움. AI가 이거 풀려면 적어도 몇 년 걸릴 듯
Timothy Gowers(필즈 메달 수상자) : 이거 다 푸는 건 고사하고, 한 문제 제대로 푸는 것도 우리가 지금 할 수 있는 걸 넘어선다
Evan Chen (국제수학올림피아드 코치) : 정말로 어려운 문제들이고, 대부분 내 능력을 뛰어넘는다
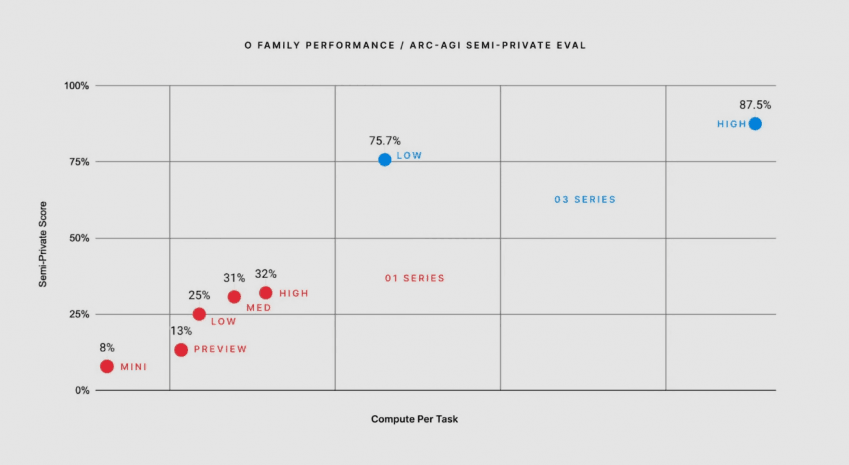
ARC-AGI (일반 추론 평가) : 진짜 인간다운 추론을 하는지 테스트하기 위해 만든 데이터셋
일반적인 사람이 풀었을 때 85% 정도의 정답률을 보임
o3는 여기서 생각 시간에 따라 76%-87%의 정답률을 보임
걍 기존 벤치딸들과는 차원이 다른 수준임
GPQA, FrontierMath, ARC-AGI 얘네들은 전체 문제는 비공개고 예시를 위한 일부 문제만 공개돼있기 때문에,
벤치 미리 학습했네 이 ㅈㄹ도 못함
- 오늘 발표에서 가장 놀라웠던 부분. NO.1
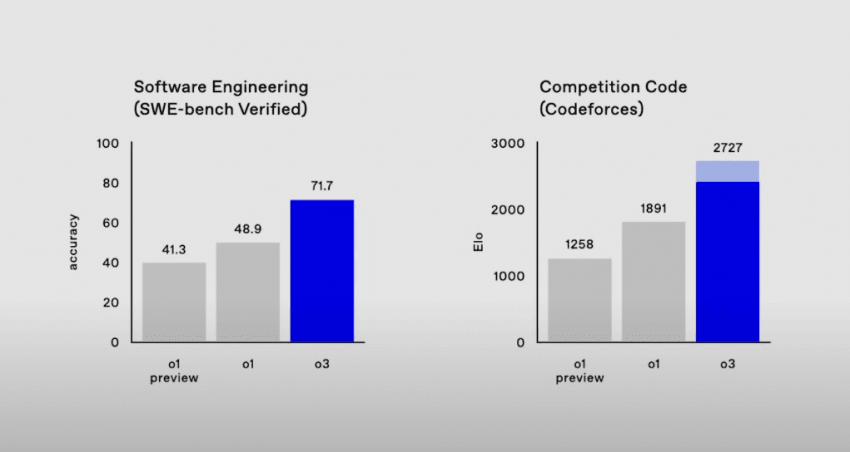
사진을 보면 알다시피 o3는 코드포스에서 2727점을 기록.
“o3는 최고 세팅에서 거의 2727과 같은 결과를 얻을 수 있었습니다.”
“샘: 아주 좋습니다. 당신(가운데 앉아있는 엔지니어 마크 첸)의 기록은 어떻습니까? 마크 첸: 저의 최고 점수는 약 2500이었습니다.”
• “우리의 수석 과학자도 이 점수를 넘지 못했는데, 이 점수는 수석 과학자 야코프의 점수를 능가합니다.”
아마 한 명이 더 높은 점수를 낸 것 같습니다.” “점수는 아마 OpenAI에서 3000점을 유지하는 사람이 한 명 있는 것 같아요.”
“그 점수도 몇 달 더 지나면 가능할 것 같아요.”
이번에 o3가 코드포스에서 2727점을 기록했으며,
가운데 앉아있는 초엘리트급 엔지니어 마크 첸(자긴 2500점대라 주장함), 심지어 일리야 후임인 야코브(현 OpenAi 수석과학자 아래 인물)마저 뛰어넘고 유일하게 오픈AI 내에서 3000점 이상인 사람이 딱 한명만 존재함…ㄷㄷㄷ
- [OpenAI] 방금 역사상 가장 똑똑한 AI가 탄생하였음
어제부터 시작된 심상치 않은 분위기

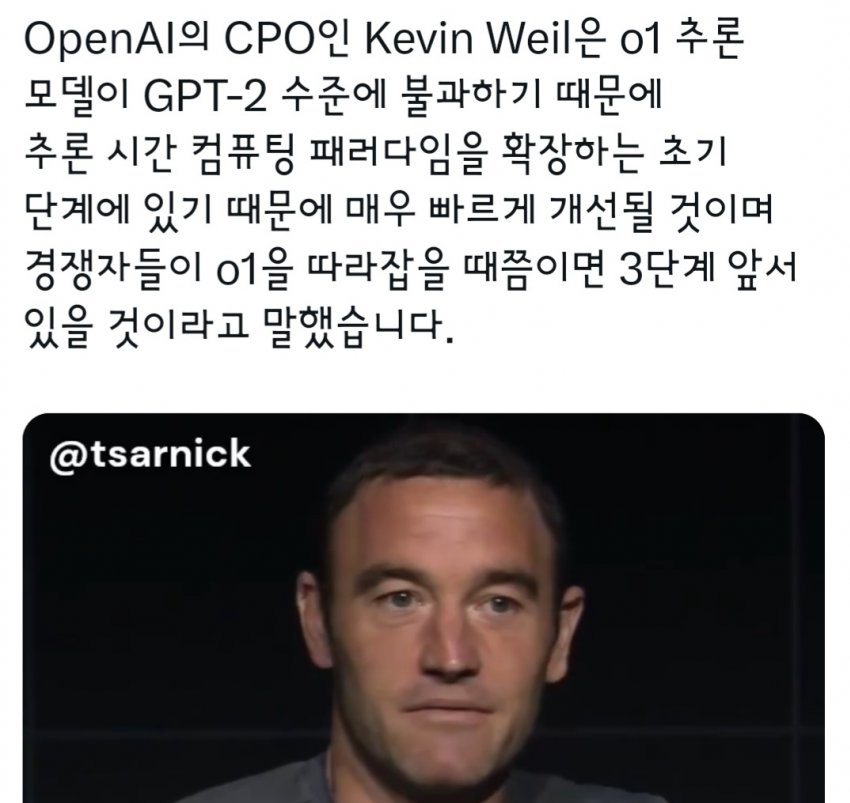

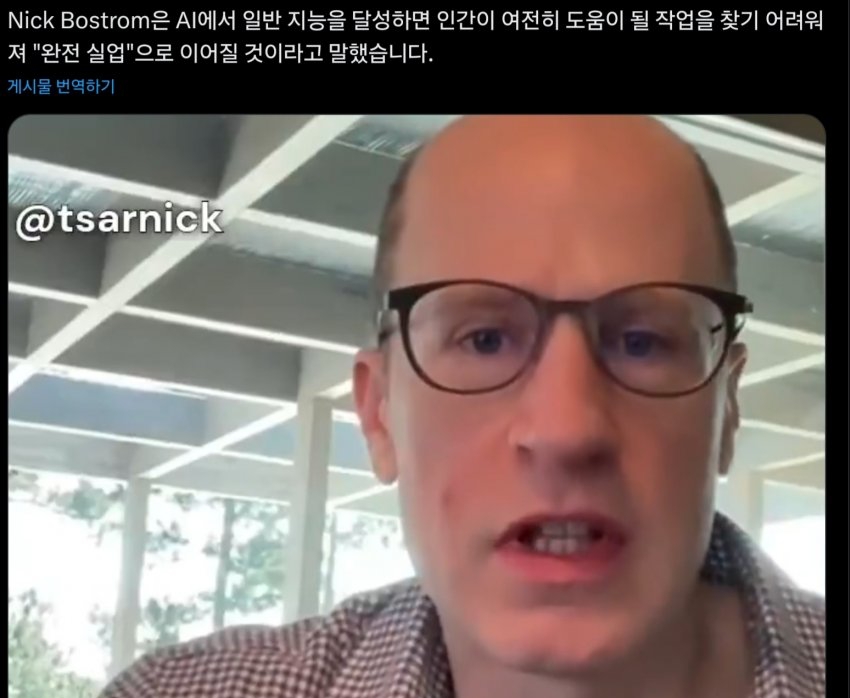
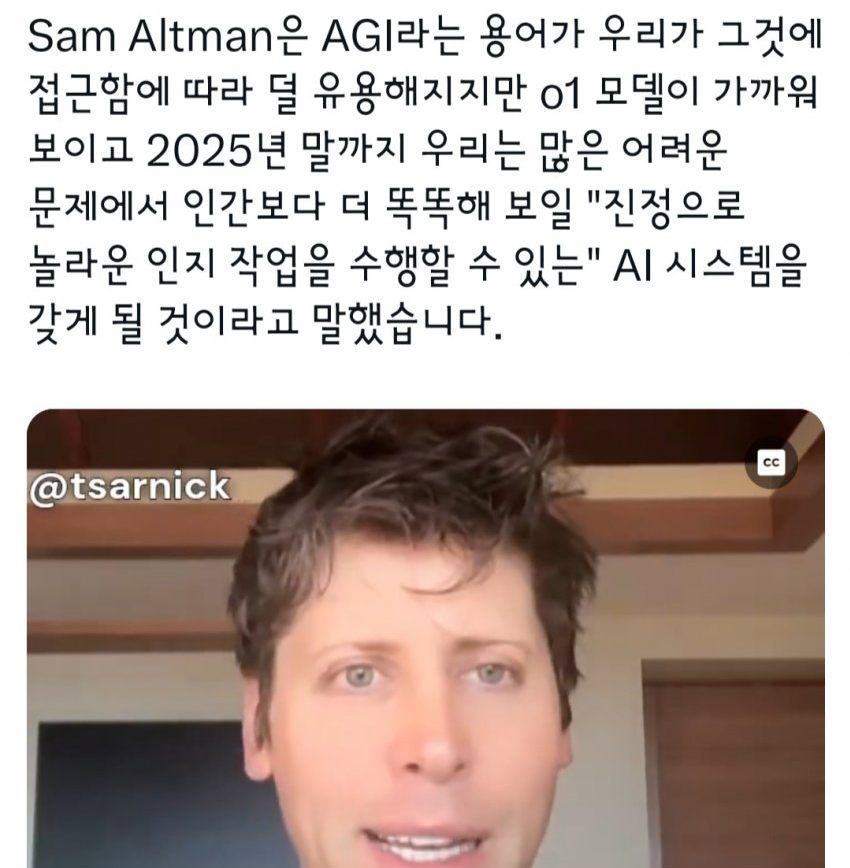
그리고 갑자기 The Information 기사가 하나 올라오는데...

그리고 약속의, 새벽 3시.

담담하게 발표하는 그들...
"O3 모델은 아주 아주 똑똑한 모델입니다. 그리고 O3 Mini 모델도 믿을 수 없을 정도로 똑똑한 모델이에요."
----------
SWE-bench Verified (Software Engineering):
실제 GitHub 이슈를 바탕으로 하여, 코드베이스를 수정하여 문제를 해결할 수 있는지를 평가. 소프트웨어 개발자로서 충분히 생산적인지를 확인.
Codeforces (Competition Code):
프로그래밍 경쟁 대회. 다양한 난이도의 알고리즘 문제를 해결하는 능력을 평가. 다양한 알고리즘 문제를 효과적으로 해결할 수 있는지를 확인.
모두 0-shots
Github 이슈, 실제 프로덕트에 대한 실질적인 해결 능력이 71%까지 올라갔다는 것을 의미함과 동시에,
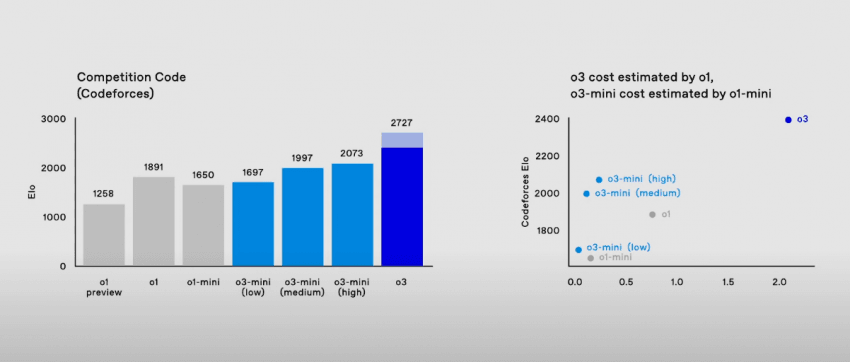
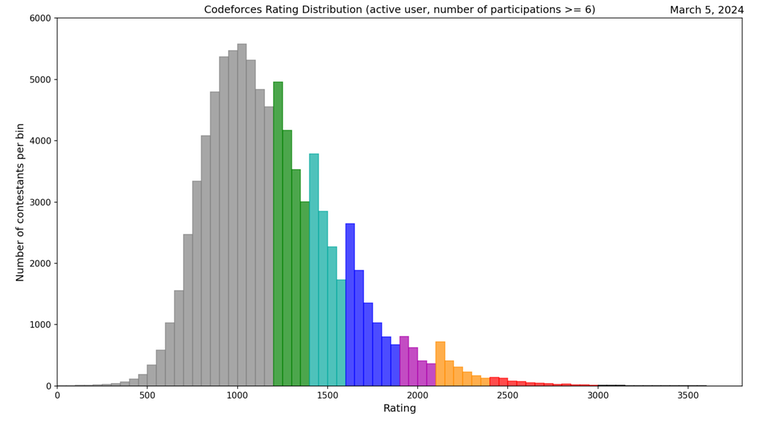


전세계 상위 0.2% 국제적인 그랜드마스터급 실력(정확히는 전세계 175위)의 알고리즘 문제 해결 능력을 보유했다는 것을 의미.
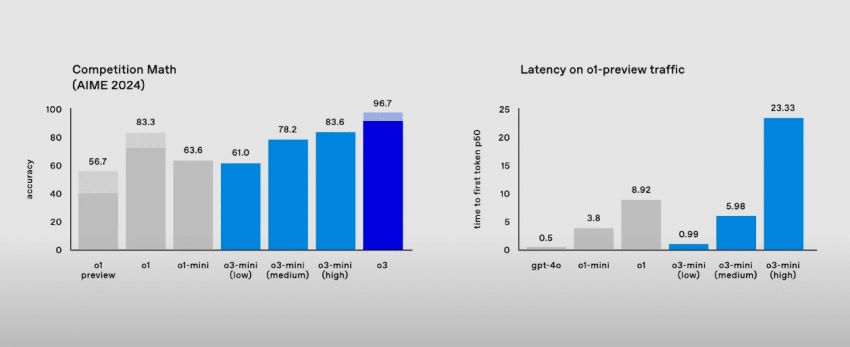
AIME 2024 (Competition Math):
중고등학생 수학 경시 대회. 기하학, 조합론, 정수론, 대수학 등 다양한 분야에서 창의적이고도 고도의 논리력과 사고력을 요구하는 문제들로 구성되며, 여기서 만점을 받는다는 것은 영재 중의 영재이자 추후 수학의 신계가 될 자들만이 가능함. 애초에 응시하는 것부터가 AMC라는 대회에서 상위 5% 미만이어야지만 응시 가능.
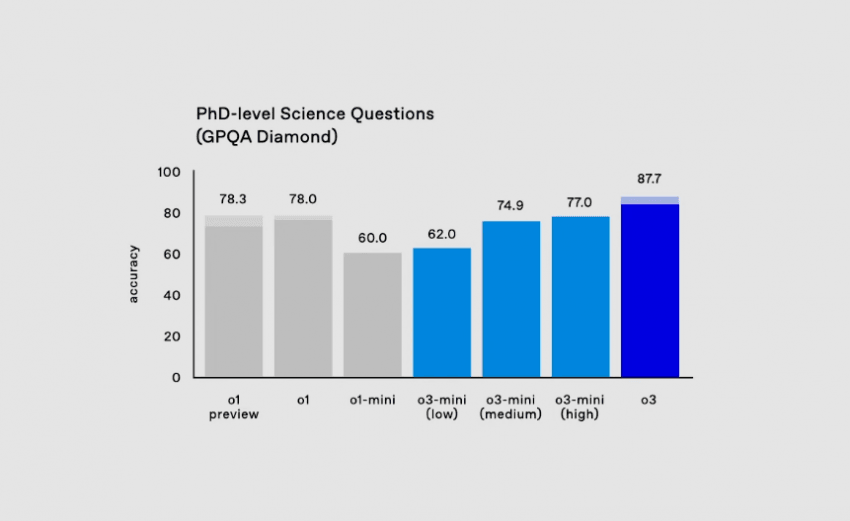
Questions (GPQA Diamond) (Phd-level Science):
박사 수준의 생물학, 물리학, 화학 문제를 해결하는 능력을 평가. 해당 분야의 박사들조차 평균 65%의 정답률밖에 달성하지 못함.
해당 부문들에 있어서 대략적으로 인간 전문가를 한참 뛰어넘었다고 볼 수 있겠다.
EpochAI Frontier Math (Research Math):
60명 이상의 최고급 수학자들이 참여하여 만든 역대급 수학 문제들. 14명의 국제수학올림피아드 금메달리스트와 필즈상 수상자들(테렌스 타오, 티모시 고워스, 리처드 보처드)이 머리를 싸매고 만든 수학 시험. 전문 수학자도 딱 한 문제 해결에 수 시간부터 수 일이 소요. 단순한 패턴 매칭이나 기존 학습 데이터만으로는 해결할 수 없는 진정한 수학적 추론 능력을 측정.
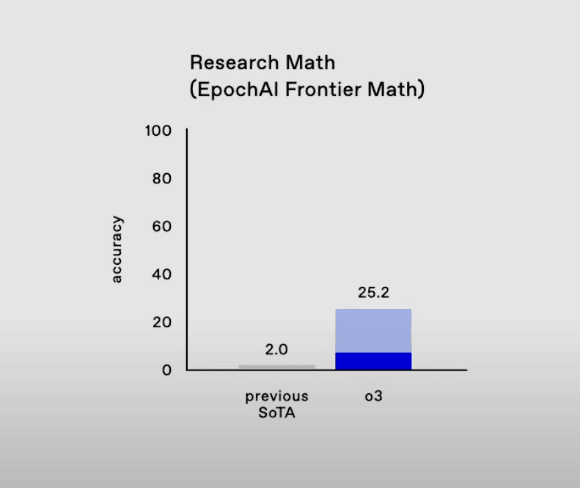
기존의 모든 AI들은 2.0%의 수준밖에 안 되었는데, o3는 25.2%까지 끌어올렸다.
ARC-AGI:
일반인공지능(AGI)의 핵심인 추상화와 추론 능력을 측정하는 테스트. 단순한 패턴 매칭이나 통계적 학습이 아닌, 진정한 지능을 측정하고자 설계.
인간 평균 수준은 70%.
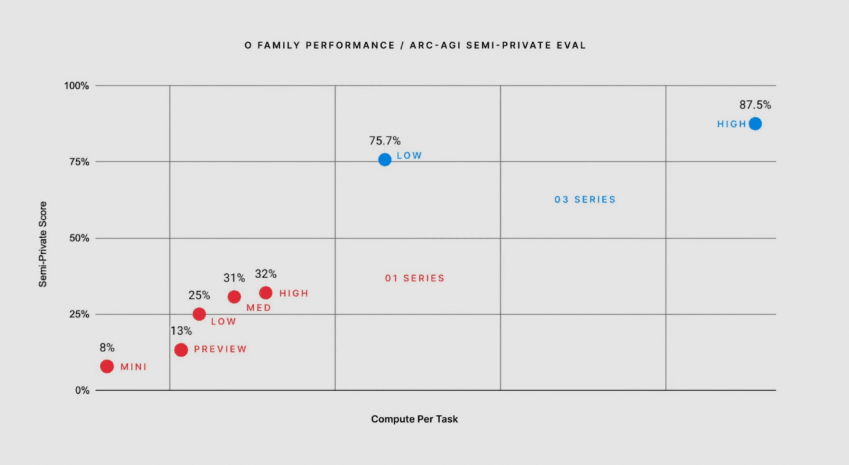
ARC Prize 창립자왈:
"OpenAI의 o3 모델은 ARC-AGI 벤치마크에서 뛰어난 성능을 보여주며, 기존 LLM의 한계를 극복하고 지식 재조합 능력을 향상시켰습니다. 이는 단순한 성능 향상을 넘어, AI가 새로운 과제에 적응하는 능력이 크게 발전했음을 보여줍니다. ARC Prize는 새로운 벤치마크를 통해 AI 연구 발전을 계속해서 추진할 것입니다."
나머지
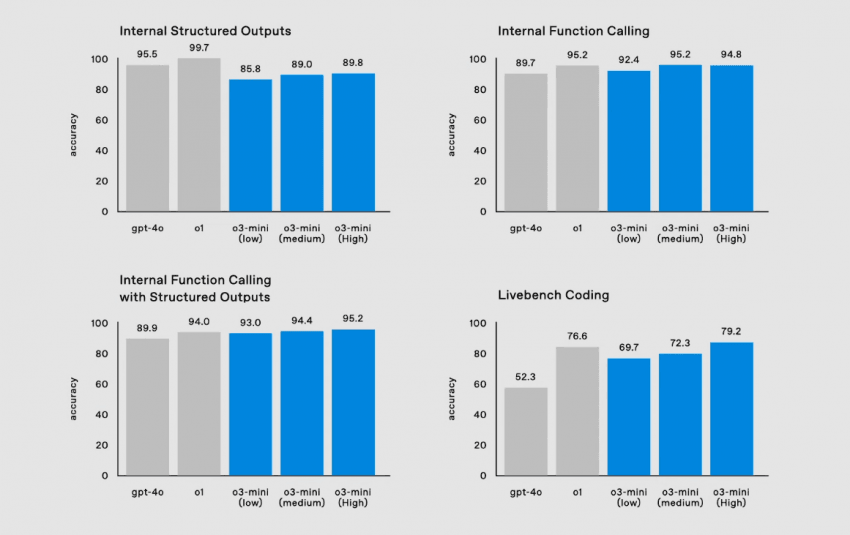
Structured Outputs:
개발자가 제공한 스키마에 따라 출력을 정확하게 구조화하는 능력. JSON, 데이터베이스, 자동화된 처리 등에 적합한 일관된 형식의 출력을 보장.
Function Calling:
외부 도구나 API와 상호작용할 수 있게 해주는 능력. 텍스트 생성을 넘어 실제 작업을 수행하고 데이터를 검색 및 처리할 수 있음.
Function Calling with Structured Outputs:
Function Calling과 Structured Outputs을 결합한 고급 능력.
LiveBench Coding:
다양한 코딩 능력 평가 시험. 문제 이해 능력, 기존 코드 기능 파악, 누락된 부분 완성 능력 등을 다양한 문제들로부터 평가.


 커뮤맨 작성
커뮤맨 작성

















































